Historique : comment on en est arrivé là ?
L’univers du stockage numérique a connu beaucoup d’évolutions ces dernières années. La consommation de données ne cesse de croître. Ces données ont ouvert de nouveaux usages, comme les réseaux sociaux, la vidéo à la demande, les objets connectés et bien d’autres.
La masse des données gérée par tous ces systèmes ont obligé à repenser la vision même de la donnée et de son usage.
Pendant bien longtemps les moyens de stockage étaient perçus comme de simples entrepôts de données, les données étant principalement conçues pour être consommées par d’autres systèmes.
Les bases de données relationnelles ont été une première percée dans la conceptualisation que les données ont une consistance et peuvent avoir des liens entres elles. Les performances et la simplicité d’usage du langage SQL a grandement aidé à son adoption. Des bases de données comme Oracle, PostgreSQL ou DB2 ont su progresser d’années en années pour gérer toujours plus de données.
Les usages évoluant, les projets ont eu besoin de croiser de plus en plus de données. Jointure après jointure, beaucoup de DBA ont prit peur en voyant comment leurs bases de données étaient malmenées. Les développeurs reprochaient un manque de souplesse tandis que les DBA reprochaient le manque de rigueur et de structuration des développeurs. Cette différence de point de vue a créé de l’incompréhension voire de la frustration entre les développeurs et DBA.
L’arrivée de la notion de Big data a chamboulé cet écosystème, forçant les différents acteurs d’un projet à renouer le dialogue. Le but était de repenser les fondements et la notion même de la donnée numérique afin de répondre à des questions essentielles :
- Quelles données doit-on stocker ?
- A quoi servent elles ?
- Quelle est leur volumétrie et leur durée de rétention ?
- Quelle structuration serait la plus adaptée à cette typologie de données ?
- et la question la plus importante, comment peut on les valoriser ?
Il n’existe pas de base de données idéale pouvant répondre à toutes les problématiques. Chacunes ont un domaine et un cadre d’utilisation particulier. On retrouve par exemple :
- Des bases de données d’indexation (ElasticSearch, Lucene, SolR) qui permettent une recherche à la fois souple est très performante
- Les bases de données hérarchiques (la plus connu étant MongoDB), dont la structuration sous forme d’arborescence facilite la recherche par catégorisation.
- Les bases de données time series (graphite, influx DB) qui sont destinées à stocker des données temporelles
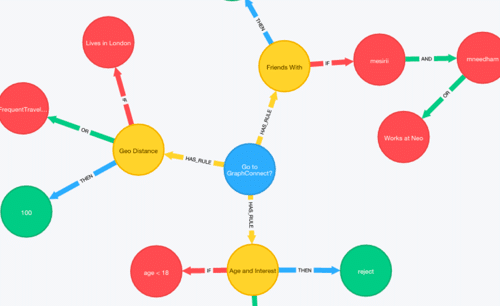
- Les bases de donneés orientés graph (Neo4j, Amazon Neptune) qui ont pour but de tirer partie des relations entres les données
- Les bases de données masse storage (cassandra) dont l’objectif est de gérer une très grande quantité de données
L’engouement pour les bases de données orientées graphe augmente d’années en années (+11% d’intérêt pour Neo4J entre décembre 2018 et décembre 2019). De nouveaux acteurs tels que Amazon Neptune devraient également aider à la démocratisation de ce type de base de données.
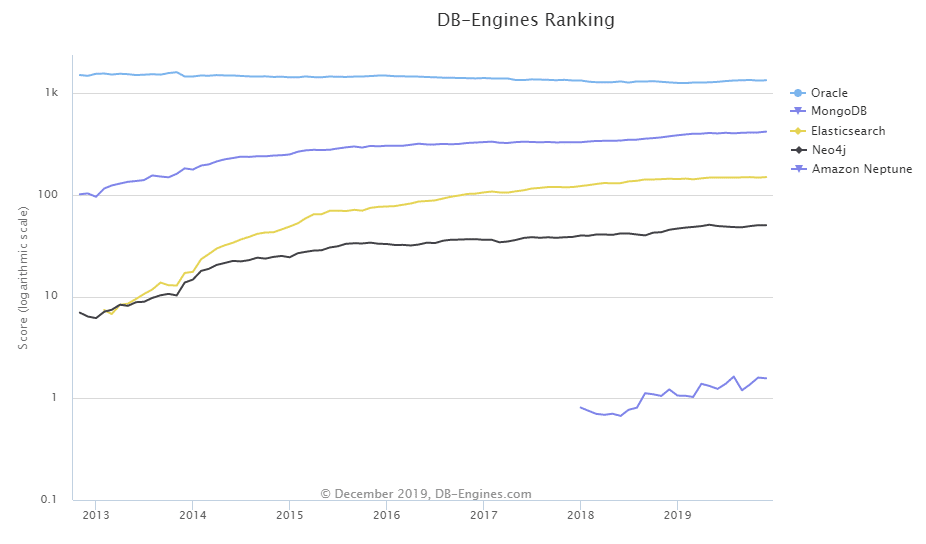
(source: https://db-engines.com/en/ranking_trend)
Les cas d’usages
Les bases de données orientés graphe servent à mettre les données en relation et à faciliter l’exploitation. La possibilité de croiser un grand nombres de données et d’apporter de l’information sur leurs liens permet de mettre en place simplement des systèmes qui serait extrêmement complexes avec d’autres technologies.
On peut définir plusieurs domaines de prédilections :
- La recommandation : C’est l’un des cas d’usage le plus courant. On retrouve ce type de logique sur les réseaux sociaux pour mettre en relation des individus. Les sites e-commerces utilisent également beaucoup de moteurs de recommandation pour proposer des produits en relation avec l’achat en cours. L’avantage d’une base de données orientés graphe est la mise à disposition de la recommendation dans un temps de réponse quasi temps réel. De plus, il n’est pas nécessaire de préparer un modèle de données au préalable. La recommandation se constitue directement via les données stockées.
- La détection de fraude : Les domaines de l’assurance et de la finance l’utilisent afin de vérifier des transactions en croisant différents indicateurs et relations complexes, permettant ainsi de quantifier le risque de fraudes.
- L’automatisation du suivi de production : Beaucoup d’entreprises ont des systèmes informatiques complexes. La mise en place d’architecture microservices apporte une plus grande complexité pour identifier les sous systèmes responsables de défaillances. Ce temps d’analyse est rapidement très coûteux. Le composant générant une anomalie n’est pas forcément celui qui est responsable de la défaillance. Avoir un système capable d’identifier, catégoriser, historiser, et retracer les scénarios amenant à une défaillance est un gain de temps et de qualité.
- Cartographier un SI ou des applicatifs : Afin d’identifier et visualiser les interractions entres les sytèmes d’informations ou les fonctionnalités.
- Médical : On retrouve son usage dans le monde médical, par exemple afin de déterminer les interactions médicamenteuses et leurs effets indésirables.
- Cartographie : Les données géo-spatiales peuvent également être exploitées pour concevoir par exemple des moteurs d’itinéraires dynamiques
Une base de données graphe c’est quoi au juste ?
Les notions de base
Elles se basent sur un concept de nœud (appelé node ou vertex) portant des propriétés. Ces propriétés sont de types simples (nombre, texte, date, etc…). Ces différents nœuds sont reliés entre eux par des relations (appelés également edge). La grande force des bases orientés graphe est que ces relations peuvent également porter de l’information.
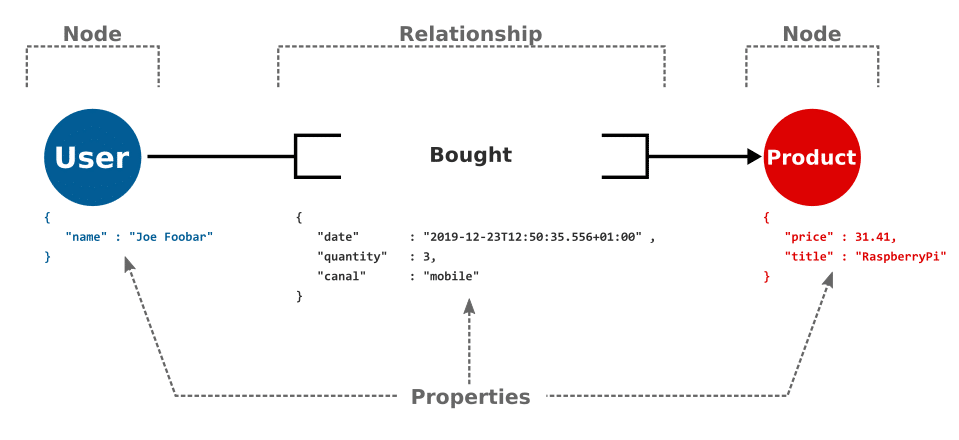
Dans le cas ci-dessus on retrouve un exemple très simple avec un utilisateur ayant acheté un produit. Cette modélisation très simpliste permet de visualiser comment les données sont mises en relation.
Le fait que les différents noeuds ne peuvent contenir que des types de données simple implique la nécessisté de découper son modèle de données en petites entités. Les différents noeuds sont typés. Les propriétés n’étant pas forcément normalisées, on peut avoir des champs différents pour un même type de noeud ou de relation. Dans les faits, il est préférable de normaliser un minimum les entités.
Les bases de données orientés graphe ont une modélisation de données naturelle et intuitive. De ce fait, des personnes fonctionnelles peuvent plus facilement comprendre et aider à cette modélisation. En relationnel, cela n’est pas forcément le cas du fait des aspects techniques comme les tables de jointures.
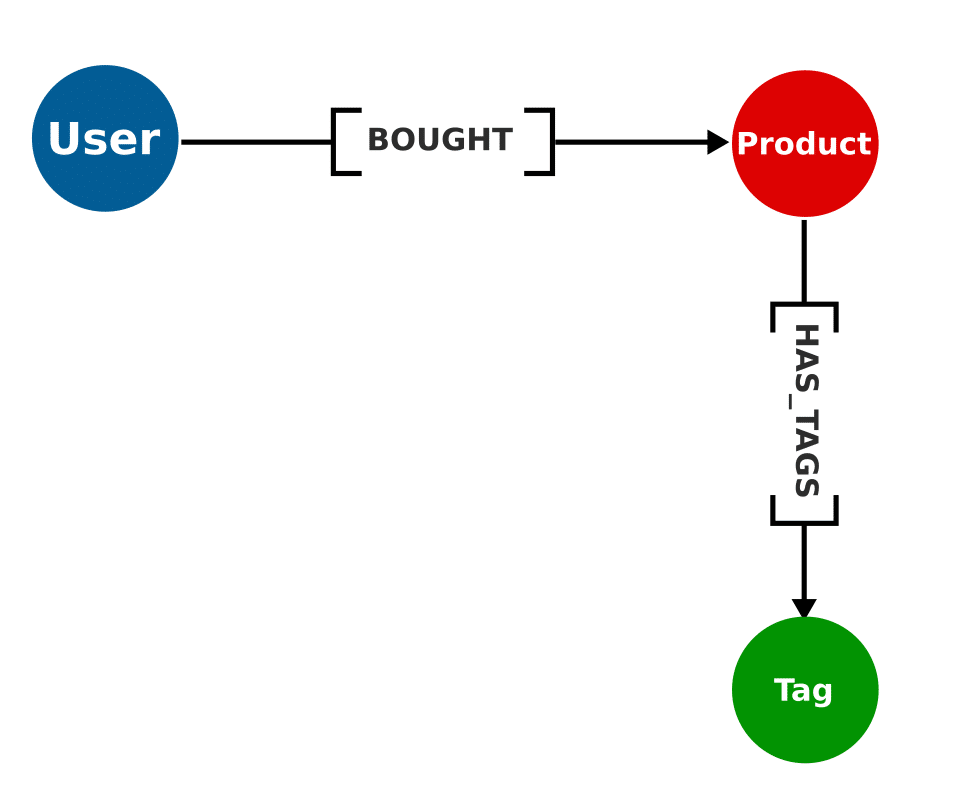
Des bases de données comme Neo4J sont des bases de données ACID (Atomicité, Cohérence, Isolation et Durabilité). Ce principe est essentiel pour garantir la fiabilité des données. Cette gestion est gérée au travers de transactions. Les modifications effctuées sur la base de données sont effectives qu’une fois la transaction validée et historisée. Les transactions sont totalement indépendantes les unes des autres.
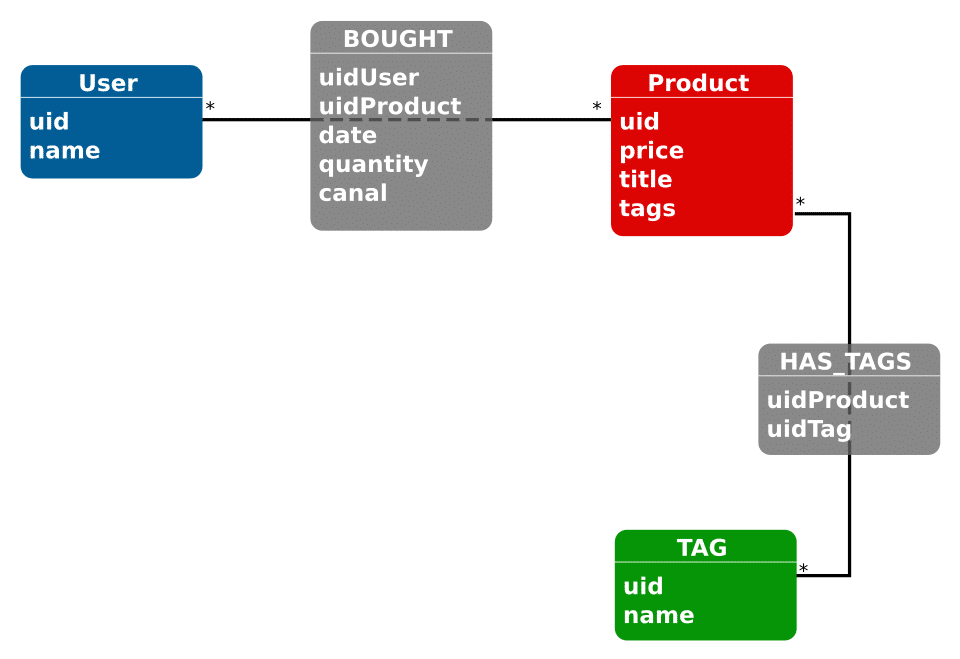
Notre cas est très simple, les deux modèles sont relativement proches. Cependant, plus on aura de relations et plus le modèle relationnel va se complexifier.
Actuellement les langages de requêtage des bases orientés graphe ne sont pas unifiés. Chaque base de données propose son langage. Un consortium mené par différents acteurs du secteurs (Neo Technology, Oracle, Amazon et d’autres) tentent d’élaborer le futur langage GQL qui sera l’équivalent du SQL pour les bases de données orientés graphe. Ce langage serait une fusion entre Cypher (langage de Neo4j), PGQL (oracle) et G-Core (Linked Data Benchmark Council). (référence : https://www.gqlstandards.org/what-is-a-gql-standard)
Le langage Cypher conçu par Neo4j est utilisé sur plusieurs bases de données orientés graphe (Neo4J, RedisGraph, AnzoGraph, …). Sa logique repose sur une symbolique en AsciiArt pour décrire la requête. Les nœuds sont représentés par des parenthèses et les relations par une flèches ayant un cartouche. Sa structuration est fortement inspirée du langage SQL. Il est possible de retourner les nœuds sélectionnés ou certaines propriétés spécifiques.
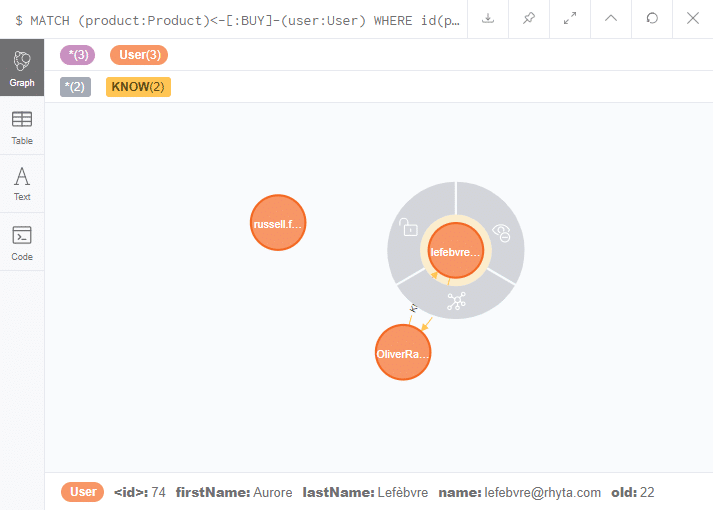
Par exemple pour récupérer la liste des utilisateurs ayant achetés un produit
[pastacode lang=”sql” manual=”MATCH%20(product%3AProduct)%20%3C-%5B%5D-%20(user%3AUser)%0AWHERE%20id(product)%20%3D%204%0ARETURN%20DISTINCT%20user” message=”” highlight=”” provider=”manual”/]
L’équivalent en SQL serait :
[pastacode lang=”sql” manual=”SELECT%20DISTINCT%20id%2C%20name%20FROM%20User%20user%0AINNER%20JOIN%20BOUGHT%20bought%20ON%20user.id%20%3D%20bought.productId%0AWHERE%20bought.productId%20%3D%204″ message=”” highlight=”” provider=”manual”/]
Le language Cypher est moins verbeux que le language SQL pour opérer des jointures grâce aux flèches remplacement les mots clés SQL. Dans le cas présent on retourne directement les noeuds de type “User”, on aura donc une liste contenant les données relatives aux utilisateurs.
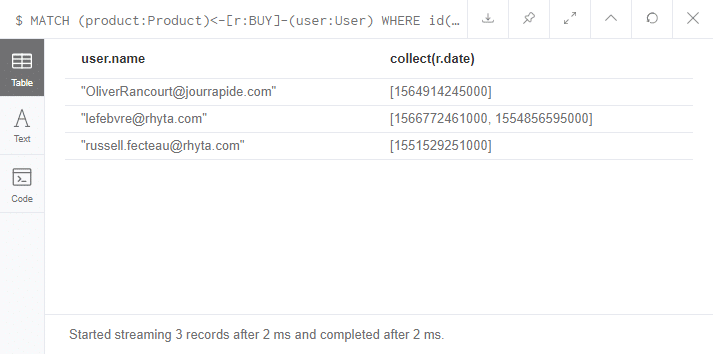
Si on souhaite ne retourner que certaines propriétés, il suffit de les lister après l’instruction RETURN. Les propriétés retournées peuvent être n’importe lesquelles parmi les propriétés issues des noeuds ou relations sélectionnées :
[pastacode lang=”sql” manual=”MATCH%20(product%3AProduct)%3C-%5Br%3ABOUGHT%5D-(user%3AUser)%0AWHERE%20id(product)%3D%7Bid%7D%0ARETURN%20user.name%2C%20collect(r.date)” message=”” highlight=”” provider=”manual”/]
Il est possible de transformer les propriétés via différentes fonctions (calcul mathématique, filtre, transformation de type,… ) ou expression en Scala.
Les performances
Dans certains cas d’usage, une base de données relationnelles ne serait pas en mesure de répondre suffisamment vite. Les performances des requêtes avec jointures en relationnel décroît avec l’augmentation du nombre de données stockées. A l’inverse les bases de données orientés graphe y sont peu sensible, c’est le nombre de connexions sur un même nœud qui réduit les performances.
Dans la présentation d’Emil Eifrem (CEO of Neo Technology : https://www.youtube.com/watch?v=UodTzseLh04), il prend pour exemple un cas d’usage où il y a 1’000 utilisateurs. Chacun d’eux est connecté à 50 utilisateurs. Pour déterminer si deux personnes sont interconnectées (en limitant au 4ème degrés de relation), une base de données relationnelles mettrait environ 2000ms à résoudre cette requête. Grâce à sa gestion des relations, un base orienté graphe pourra résoudre cette même requête en 2ms.
Le nombre d’utilisateurs n’impactant pas la gestion des relations (chacun d’eux conservant 50 relations), pour 1 millions d’utilisateurs le temps restera de 2ms pour une base orientés graphe. Une base relationnelle aurait beaucoup de difficulté pour analyser les différentes possibilités, et mettrait plusieurs jours à répondre.
Pour comprendre pourquoi une base de données graphe n’est pas sensible à la volumétrie, il est nécessaire de comprendre son fonctionnement: le stockage physique des relations. Dans l’exemple cité, au lieu de parcourir la table de jointure pour récupérer les utilisateurs connectés, la base orienté graphe va avoir accès directement aux relations. Elle va donc potentiellement obtiendra 50 utilisateurs à la première itération. A la seconde chaque utilisateur peut avoir 50 relations, elle obtiendra donc potentiellement 2’500 utilisateurs, et ainsi de suite sur les 4 niveaux.
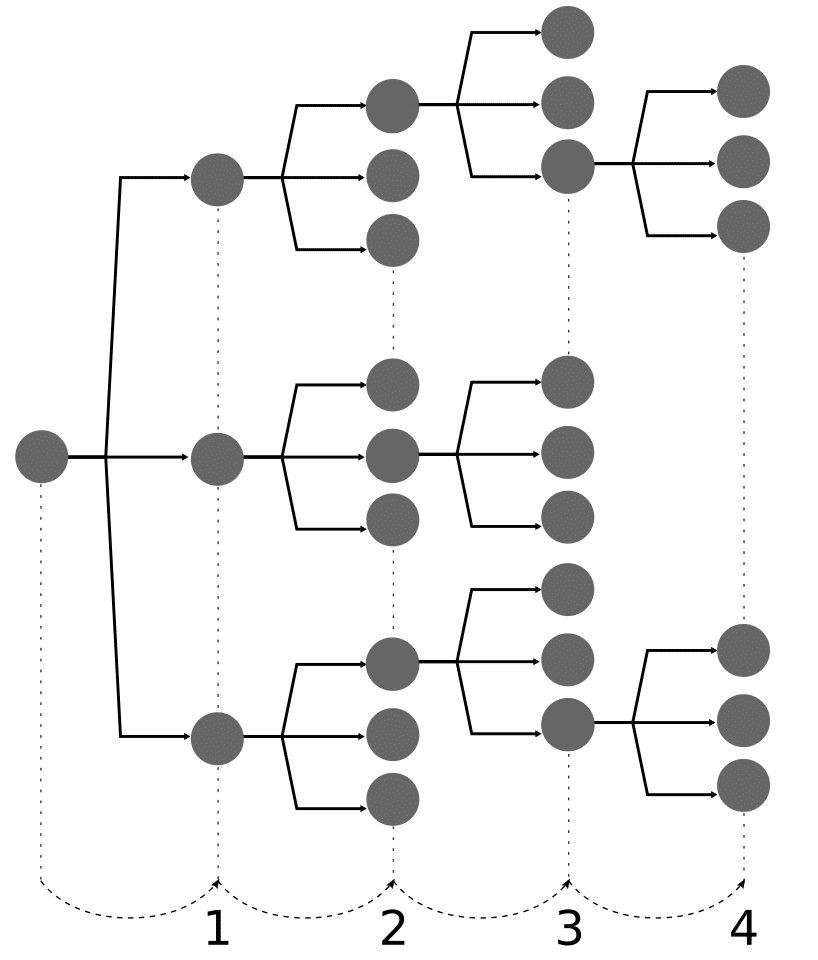
Une base relationnelle ne connaît pas à l’avance les relations entres les utilisateurs. Elle est obligée de parcourir intégralement sa table de jointures pour obtenir les relations. Étant donné que nos 1’000 utilisateurs ont chacun 50 relations on aura donc une table de jointures avec 50’000 entrées. Comme pour la base orienté graphe, on aura nos 50 utilisateurs potentiels à la fin de la première itération. A la seconde itération, pour ces 50 utilisateurs on va devoir parcourir notre table de jointure pour récupérer leurs relations, et ainsi de suite…
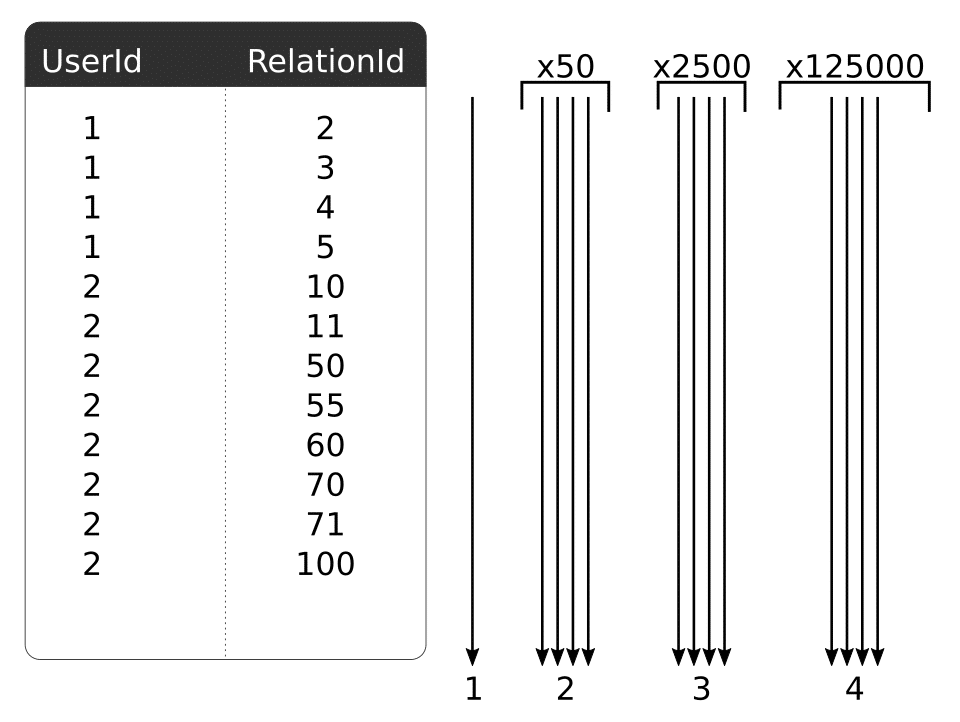
Sans mécanisme sophistiqué, il est impossible pour une base de données relationnelles de répondre avec des temps acceptables sur ce type de problématique.
Les différentes bases orientés graphe
Il existe différentes bases de données orientés graphe. Chacunes d’entre elles ont leurs spécificités. Certaines comme AWS Nepture ou Microsoft Cosmos-db sont spécifiques à une plateforme cloud en particulier.
Neo4J est actuellement la base de données orientés graphe la plus populaire. Sa maturité et son intégration dans des frameworks tels que Spring data ou Hibernate ORM en font un choix de prédilection. Neo4j permet également d’avoir le choix de son mode de déploiment, soit sur son infrastructure, soit dans le cloud (Amazon, Google, Microsoft ou Neo4j Aura).
Plusieurs grandes entreprises ont fait confiances à Neo4J pour les aider dans des domaines variés (https://neo4j.com/customers/):
- UBS : afin d’analyser les risques financier (https://neo4j.com/case-studies/ubs-case-study/)
- Novartis Pharmaceuticals : la mise en relation de données biologiques permet d’aider leurs chercheurs à trouver de nouveaux médicaments (https://neo4j.com/blog/stephan-reiling-senior-scientist-novartis/)
- EBay : la mise en place de Neo4j a servi pour améliorer l’achat via le bot conversationnel
- US Army : Ils ont mis en place Neo4j afin d’améliorer la traçabilité sur la maintenance des équipements (https://neo4j.com/case-studies/us-army/)
Conclusion
Les bases de données graphe offrent un très grand potentiel sur l’exploitation de données relationnelles. Son concept de base est simple mais permet une grande richesse grâces aux interconnexions entres les différentes données. D’un certain point de vue cette notion est plus naturelle pour un être humain. Les relations sont conçues avant tout à partir de concepts fonctionnels.
Les différentes bases de données commencent à avoir une bonne maturité justifiée et appuyée par la standardisation en cours. Cependant comme toute nouvelle technologie, il est nécessaire de compter sur phase de montée en compétence des équipes ( aussi bien côté développement que du côté opérationnel ). Cette apprentissage sera toutefois facilité par la richesse des documentations présentes sur les sites des éditeurs.
Dans notre prochain article nous ferons un focus plus particulier et plus technique sur la base de données graphe Neo4j.