
Git est devenu le standard pour la gestion de code source. Pour compléter notre formation Git, voici un guide pour utiliser au mieux ses fonctionnalités dans un esprit DevOps.
Garder une unique branche principale toujours prête à partir en production
Il est primordial que la branche de travail principale soit toujours prête à partir en production. Cela passe par le lancement d’un harnais de tests automatisés suffisamment solide à chaque commit. Le fait de travailler avec plus d’une branche principale (par exemple master/develop) nous apparaît être une complexité inutile sauf dans des conditions particulières :
- Il existe un ensemble de tests manuels pour être éligible à la production. Nous défendons évidemment que ces tests devraient être automatisés.
- Plusieurs sous équipes, ou plus de 10 personnes travaillent dans le même dépôt. Créer des branches par sous équipe peut alors être un moyen d’assurer la stabilité, même si cette manière de travailler est douloureuse et nécessitera certainement une personne dédiée à l’intégration.
- La mise en production nécessite une synchronisation étroite avec d’autres équipes. Même si des réflexions sur les frontières applicatives et sur la méthodologie méritent alors d’être posées, il existe effectivement des contextes (en particulier sur des applications legacy) où il n’est pas possible de travailler autrement.
Utiliser des features branches
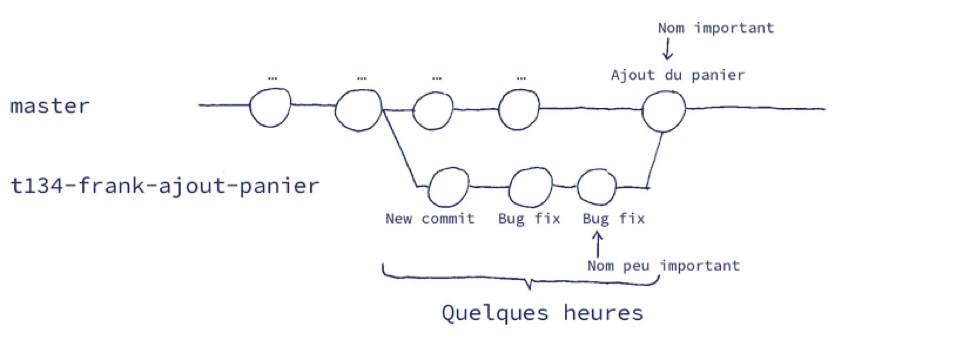
Créer une branche pour chaque nouvelle tâche est une bonne pratique sous Git (on parle de “feature branch”).
- Ces branches doivent garder une durée de vie aussi courte que possible (idéalement, quelques heures).
- Lorsque le merge vers la branche principale n’est pas réalisé via un outil, il est préférable d’utiliser l’option “–no-ff” (no fast forward) afin de ne pas polluer l’historique de la branche principale.
- Si la branche de travail est amenée à vivre davantage que quelques heures (tache longue et non découpable, oubli…), faire des rebases ou des merges réguliers depuis la branche principale afin de limiter les divergences.
Même lorsque l’on travaille seul, utiliser des features branches est une bonne pratique dès lors que le projet devient sérieux :
- Cela assure la stabilité de la branche principale, qui doit rester apte à partir en production en permanence.
- On dispose, in fine, de la possibilité d’abandonner le travail (de ne pas le merger).
- Accessoirement, cela permet un gain en lisibilité dans l’historique de la branche principale tout en gardant la possibilité de faire autant de commits que souhaité durant le développement.
Les Pull Requests ne correspondent pas systématiquement à une validation manuelle
Fusionner une feature branche dans la branche de travail principale passe par une Pull Request (PR).
- Cette PR ne nécessite pas systématiquement une validation manuelle. Il est de la responsabilité du développeur de différencier les PRs qui améliorent l’état du projet sans qu’il n’y ai débat, de celles qui nécessitent une revue de code immédiate (code critique pour la sécurité, modifications structurelles, nouvelles fonctionnalités…). Par ailleurs, des situations particulières et nous l’espérons temporaires peuvent justifier des validations manuelles systématiques au sein d’une équipe :
- Absence d’analyse de code automatique (par exemple, SonarQube)
- Contributeur pas en confiance sur le projet (par exemple, n’ayant pas commité sur le projet depuis longtemps)
- Couverture des tests lancés automatiquement insuffisante. Des cas particuliers peuvent légitimer cette situation, par exemple pour de l’IaC (Infrastructure as Code).
- Cependant, une Pull Request devrait systématiquement passer par une validation automatique (lancement des tests, des différentes solutions d’analyse de code…). Cela assure que la fusion reste éligible à la mise en production.
Revue de code
Même si nous dissocions la revue de code des Pull Requests, le merge reste un moment propice pour une revue de code.
- Il est primordial pour la vélocité du projet que les demandes de revue de code soient traitées comme des tâches prioritaires.
- Une revue de code ne doit pas être une validation, au risque de brider le partage, de créer des frustrations, de limiter la vélocité et de limiter la motivation des équipes.
- C’est par contre un moment propice au partage de bonnes pratiques entre collègues.
- Une revue de code permet souvent de prévenir l’apparition de problèmes d’architecture, et d’éviter les problèmes fonctionnels (mauvaise compréhension de la fonctionnalité demandée).
- Cela ne remplace pas l’analyse automatique de code, ni la revue de code périodique par un développeur expérimenté.
- Cela ne remplace pas non plus le pair programming, qui est particulièrement adapté aux situations complexes (modification d’un code mal testé, des couches de sécurité, de l’architecture…) et durant les phases d’apprentissage.
Et la production ?
Idéalement, la mise à jour de la branche de travail principale doit amener à un déploiement automatique en production, sans aucune action manuelle. Mais cela nécessite de nombreux pré-requis :
- Un excellent niveau de confiance dans les tests.
- La possibilité technique de livrer en continu, en particulier sans interruption de service.
- Un monitoring de qualité, permettant de lever rapidement une alerte en cas de défaillance.
Nos remerciements à Alexandre Lefevre et Kevin Fontaine pour la relecture.


