Introduction
Dans l’article précédent nous avons expliqué les principaux concepts d’une base de données orientée graphe. Ce type de base de données est conçu pour permettre de gérer les relations entre les données. Elle simplifie la résolution de problèmes complexes tels que la recommandation, la mise en relation ou la détection d’anomalies. Ces cas fonctionnels complexes seraient très longs à résoudre via une base de données relationnelle classique.
Nos données sont stockées sous formes de nœuds interconnectés via des liens (appelés également edge). Les nœuds peuvent contenir uniquement des données simples (nombre, chaînes de caractères ou autre) tout comme les relations.
Les différents éditeurs proposant des bases relationnelles sont très connus (Oracle, PostgreSQL, IBM DB2, … ). Les éditeurs des bases orientés graphe le sont moins. Cependant il y en a un qui semble sortir du lot: Neo technologie avec sa base de données Neo4J.
Neo4J est apparu en 2007, ce qui en fait l’un des précurseur des technologies orientées graphe. Cette base de données est conçue en Java et Scala, cela permet d’enrichir facilement la base de données via des plugins spécifiques.
Neo4J est une base de données OpenSource sous licence GPLv3. Deux versions sont disponibles :
- La version communautaire, gratuite, pouvant servir pour un faible volume de données ou des données volatiles ne nécessitant pas de redondance. Idéal pour des POC ou des petits projets.
- La version Entreprise. Elle conçue pour gérer un très grand volume de données de façon totalement résilientes.
La version Enterprise est également disponible en version Cloud, facilitant d’autant plus son exploitation. Elle est disponible soit via la plateforme Neo4J Aura ou celle d’ Amazon AWS.
Lancement
Afin d’installer et lancer Neo4j il existe plusieurs choix :
- Soit on télécharge l’archive de Neo4J directement sur le site de Neo technologie (https://neo4j.com/download-center) puis il suffit de lancer le script
{NEO4J_HOME}/bin/neo4j.{bat|sh} - Soit on utilise l’image docker
docker run -p7474:7474 -p7687:7687 --volume=$HOME/neo4j/data:/data neo4j:latest. L’avantage de l’image docker étant sa rapidité de mise en place. C’est d’autant plus intéréssant si l’on souhaite réaliser ses premiers pas avec Neo4J. - Il est également possible d’embarquer Neo4J dans une application Java en ajoutant simplement une dépendance à son projet (
org.neo4j:neo4j:3.5.14)
Par défaut l’identifiant administrateur est neo4j et le mot de passe neo4j. Bien entendu ces informations sont à modifier après le premier démarrage.
Si le choix se porte sur la version docker, il est recommandé, s’il on souhaite tester pleinement la base de données, de configurer ses volumes afin d’avoir accès aux fichiers de logs, configuration, répertoire de plugins et autres.
[pastacode lang=”bash” manual=”docker%20run%20–name%20neo4j%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%5C%0A%20%20%20%20%20%20%20%20%20%20%20-p7474%3A7474%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%5C%0A%20%20%20%20%20%20%20%20%20%20%20-p7687%3A7687%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%5C%0A%20%20%20%20%20%20%20%20%20%20%20-d%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%5C%0A%20%20%20%20%20%20%20%20%20%20%20-v%20%24%7BNEO4J_HOME%7D%2Fdata%3A%2Fdata%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%5C%0A%20%20%20%20%20%20%20%20%20%20%20-v%20%24%7BNEO4J_HOME%7D%2Flogs%3A%2Fvar%2Flib%2Fneo4j%2Flogs%20%20%20%20%20%20%20%20%5C%0A%20%20%20%20%20%20%20%20%20%20%20-v%20%24%7BNEO4J_HOME%7D%2Fimport%3A%2Fvar%2Flib%2Fneo4j%2Fimport%20%20%20%20%5C%0A%20%20%20%20%20%20%20%20%20%20%20-v%20%24%7BNEO4J_HOME%7D%2Fconf%3A%2Fvar%2Flib%2Fneo4j%2Fconf%20%20%20%20%20%20%20%20%5C%0A%20%20%20%20%20%20%20%20%20%20%20-v%20%24%7BNEO4J_HOME%7D%2Fplugins%3A%2Fvar%2Flib%2Fneo4j%2Fplugins%20%20%5C%0A%20%20%20%20%20%20%20%20%20%20%20–env%20NEO4J_AUTH%3Dneo4j%2Ftest%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%5C%0A%20%20%20%20%20%20%20%20%20%20%20neo4j%3Alatest” message=”” highlight=”” provider=”manual”/]
Une fois démarrée, l’interface de gestion de Neo4J est disponible à l’URL http://localhost:7474/browser/
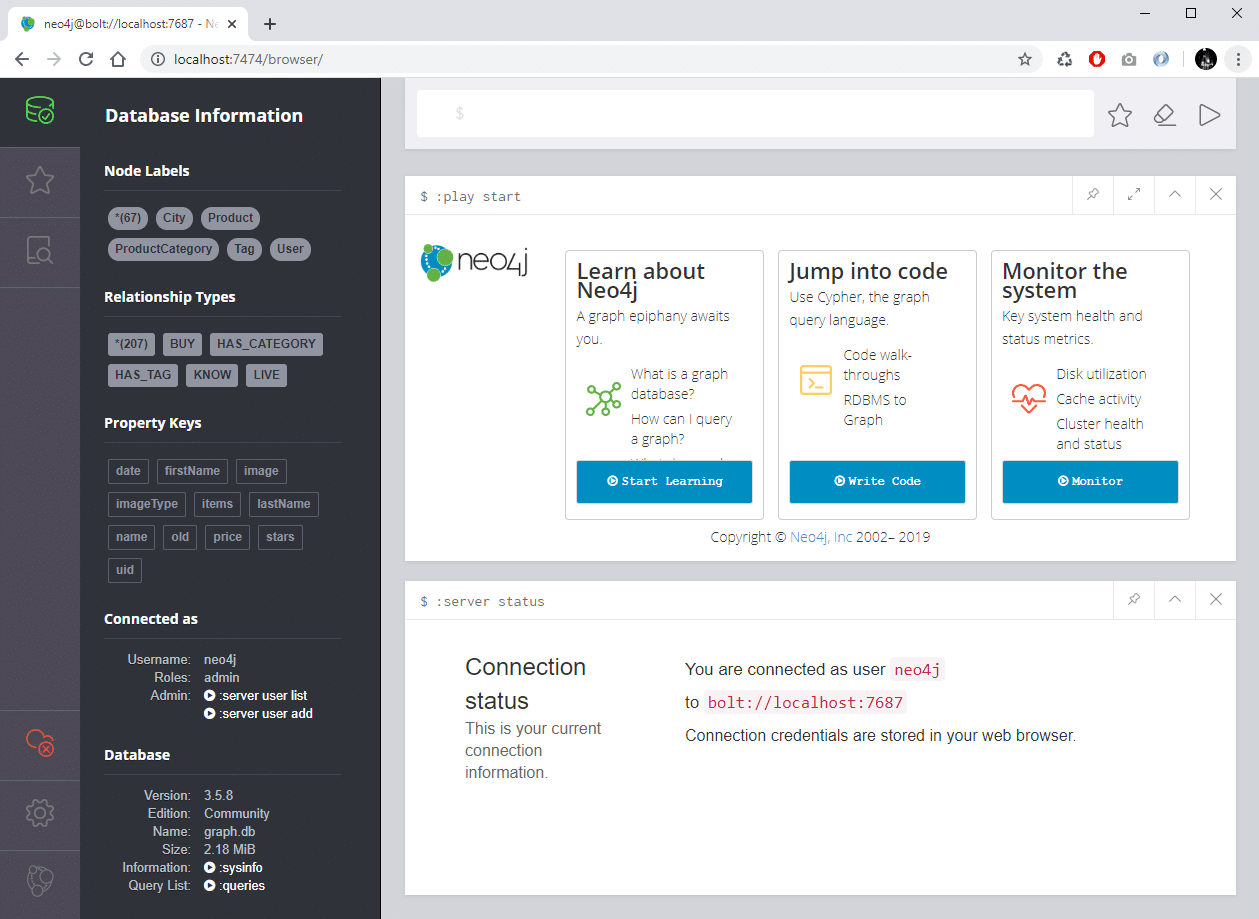
Le langage Cypher
Le langage Cypher est très riche mais permet tout de même une progression simple dans son apprentissage. La documentation de Neo4J à son sujet est très bien fournie (https://neo4j.com/docs/cypher-manual/current/).
La grande force de Cypher est de proposer un langage synthétique tirant parti d’une approche en ASCII art. Les différents nœuds sont symbolisés par des parenthèses, les relations par des flèches. Ce langage est conçu en scala, ce qui lui confère une grande puissance dans le traitement des informations.

Lorsque l’on sélectionne un nœud, on peut l’affecter à une variable. Cette variable sera dès lors utilisable pour la suite de la requête. Il en va de même pour les relations.
Il est préconisé d’avoir des noms de type de nœuds définis en camel case (exemple MonTypeDeNoeud) et les types de relations définis en snake case (exemple MON_TYPE_DE_RELATION).
Lire des informations
La première étape dans l’apprentissage de Cypher est de sélectionner des données. Bien que le langage ressemble beaucoup au SQL, il existe des différences.
[pastacode lang=”sql” manual=”MATCH%20(p%3AProduct)%20RETURN%20p%20LIMIT%2025″ message=”” highlight=”” provider=”manual”/]
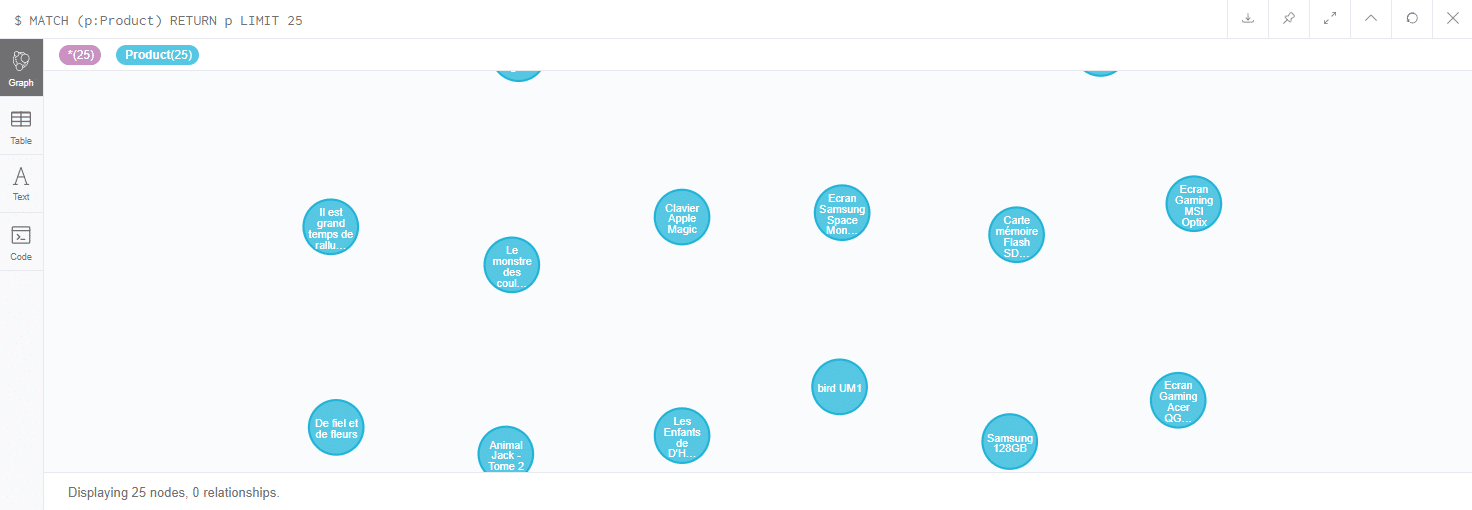
L’instruction MATCH peut faire penser au SELECT que l’on retrouve en SQL. Cependant son comportement n’est pas le même. Son approche se rapproche plus de celle d’un filtre. Dans le cas du MATCH, spécifier une condition est obligatoire. Si Neo4J ne trouve pas le type de nœud ou la relation décrite, aucune donnée ne sera renvoyée. Afin de retourner des données il doit être couplé avec l’instruction RETURN.
Comme en SQL il est vivement recommandé d’imposer une limite. Dans le cas décrit ci-dessus on limite donc le résultat à 25 éléments.
Tout comme en SQL, il est possible de faire une sélection par rapport à une liste d’éléments.
[pastacode lang=”sql” manual=”MATCH%20(p%3AProduct)%20WHERE%20id(p)%20IN%20%5B10%2C19%2C40%5D%20%20RETURN%20p” message=”” highlight=”” provider=”manual”/]
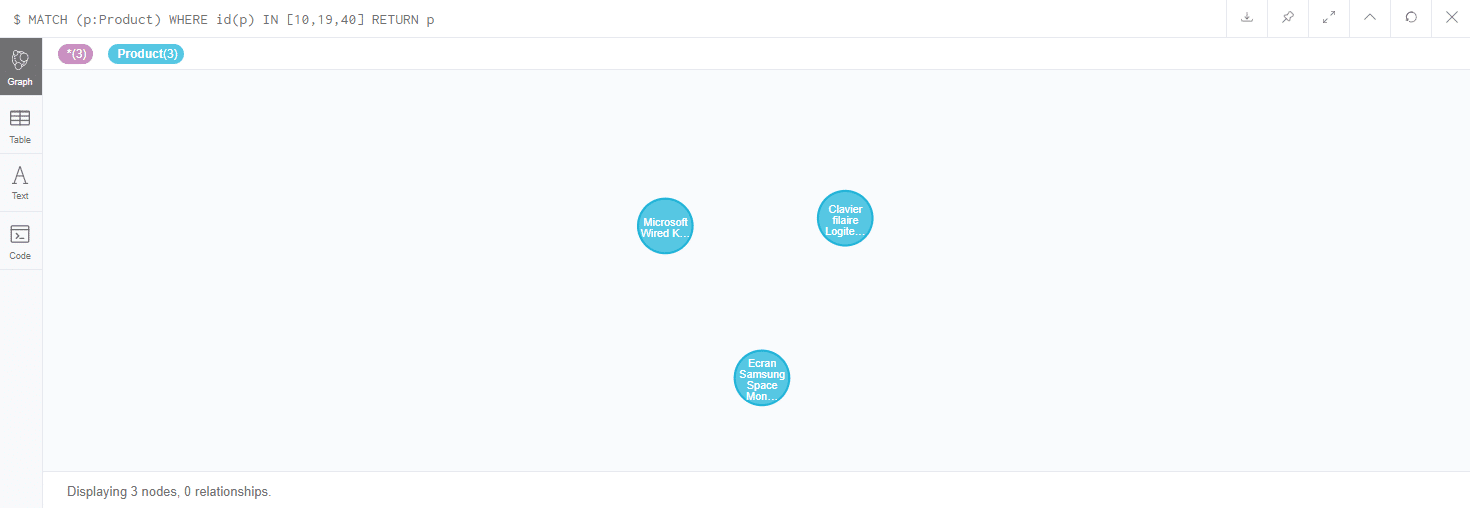
Il est aussi possible de chaîner les instructions, que ce soit via l’instruction MATCH ou autres.
[pastacode lang=”sql” manual=”MATCH%20(product%3AProduct)%0AMATCH%20(product)-%5B%3AHAS_CATEGORY%5D-%3E(category%3AProductCategory)%20WHERE%20category.name%20%3D%20%22book%22%0ARETURN%20product%2Ccategory%20LIMIT%2025″ message=”” highlight=”” provider=”manual”/]
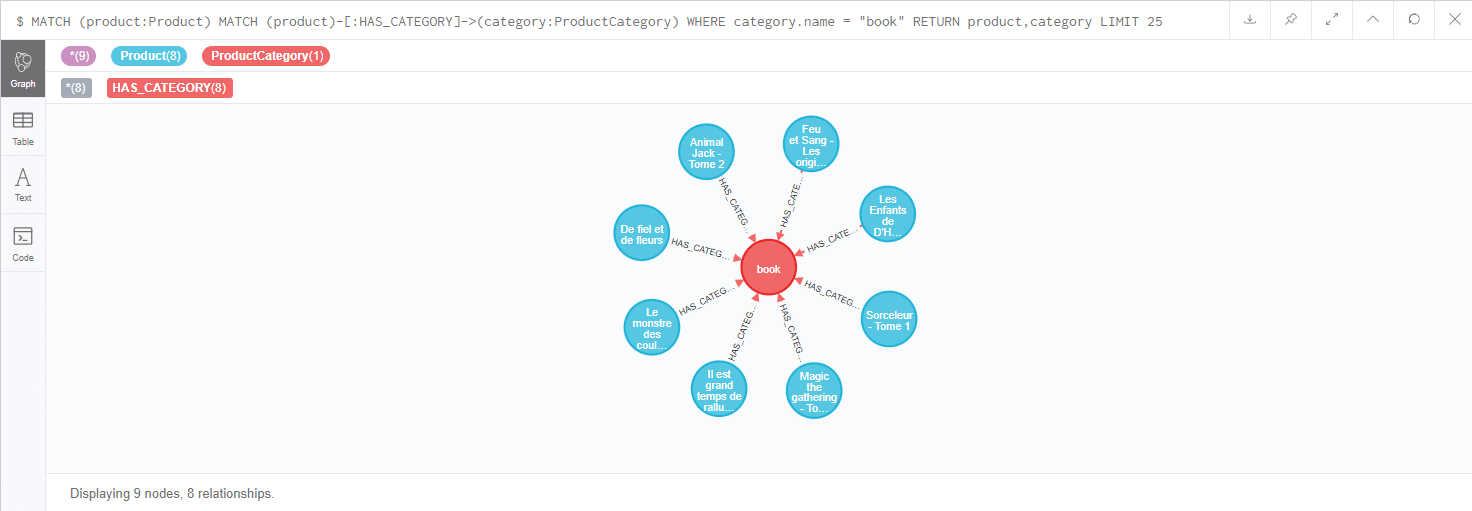
Dans ce cas chaque instruction MATCH doit être validée pour renvoyer des données. Dans le cas où l’on aurait une condition optionnelle, elle doit être explicitée via l’instruction OPTIONAL. Les OPTIONAL MATCH doivent être déclarées après les conditions non optionnelles.
[pastacode lang=”sql” manual=”MATCH%20(product%3AProduct)%0AMATCH%20(product)-%5B%3AHAS_CATEGORY%5D-%3E(category%3AProductCategory)%20WHERE%20category.name%20%3D%20%22book%22%0AOPTIONAL%20MATCH%20(product)-%5B%3AHAS_TAG%5D-(tag%3ATag)%0ARETURN%20product%2Ccategory%2Ctag%20LIMIT%2025″ message=”” highlight=”” provider=”manual”/]
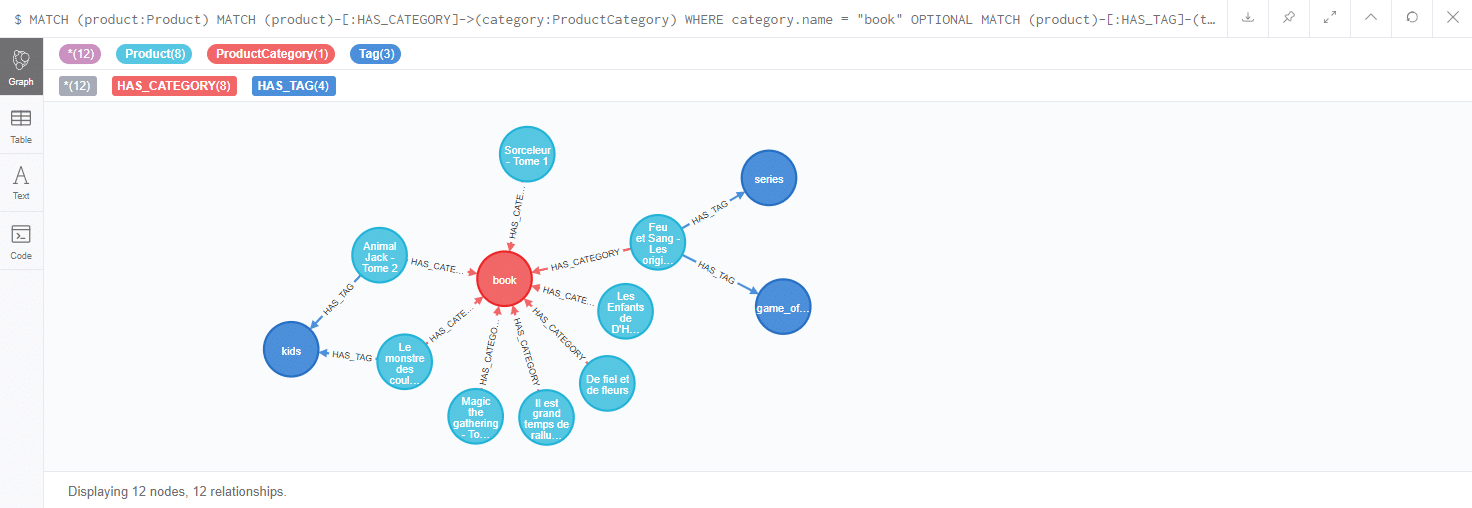
Dans le cas présent tous les produits n’ont pas de tag associé. Dans le cas où un tag serait rattaché au produit il sera retourné. Si la condition OPTIONAL n’avait pas été déclarée, seul les produits ayant un tag aurait été retournés.
Le but d’une base de données orienté graphe est de permettre le parcours des relations entre les différents nœuds. Dans le cas ci-dessus on cherche à récupérer les différents produits rattachés à la catégorie book. Cela est réalisé en désignant le type de relation HAS_CATEGORY, et en appliquant une condition sur le nom de la catégorie (dans le cas présent book). Les différents produits retournés auront, dans ce cas, tous la même catégorie.
[pastacode lang=”sql” manual=”MATCH%20(user%3AUser)%20WHERE%20user.name%3D%22AubreyLesage%40rhyta.com%22%0AMATCH%20(user)-%5B%3AKNOW*0..2%5D-%3E(knowUsers%3AUser)%20WHERE%20NOT%20knowUsers.name%3D%22AubreyLesage%40rhyta.com%22%0AMATCH%20(knowUsers)-%5B%3ABUY%5D-%3E(otherProduct%3AProduct)%0ARETURN%20otherProduct%2C%20knowUsers” message=”” highlight=”” provider=”manual”/]
Le cartouche présent sur la relation (les éléments entre crochets) est optionel. Il est utile pour qualifier le type de relation et potentiellement affecter la relation sur une variable pour récupérer ses propriétés. Si ces informations ne sont pas utiles, il est possible de les omettre. Il en va de même pour la définition du nœud où le type ou l’intégralité de la définition peuvent être omis.
[pastacode lang=”sql” manual=”%2F%2F%20OUTGOING%20for%20a%2C%20INCOMMING%20for%20b%0AMATCH%20(a)–%3E(b)%0A%0A%2F%2F%20UNDIRECTED%0AMATCH%20(c)%3C–%3E(d)%0A%0A%2F%2F%20ANY%0AMATCH%20(e)–()” message=”” highlight=”” provider=”manual”/]
Le sens des relations a son importance, la flèche définit cette orientation. Sur le même principe, si le sens de la relation n’importe pas sur la requête, il peut être omis.
Bien entendu, les performances sont impactées par le manque de précision sur les typages et sur les directions des relations.
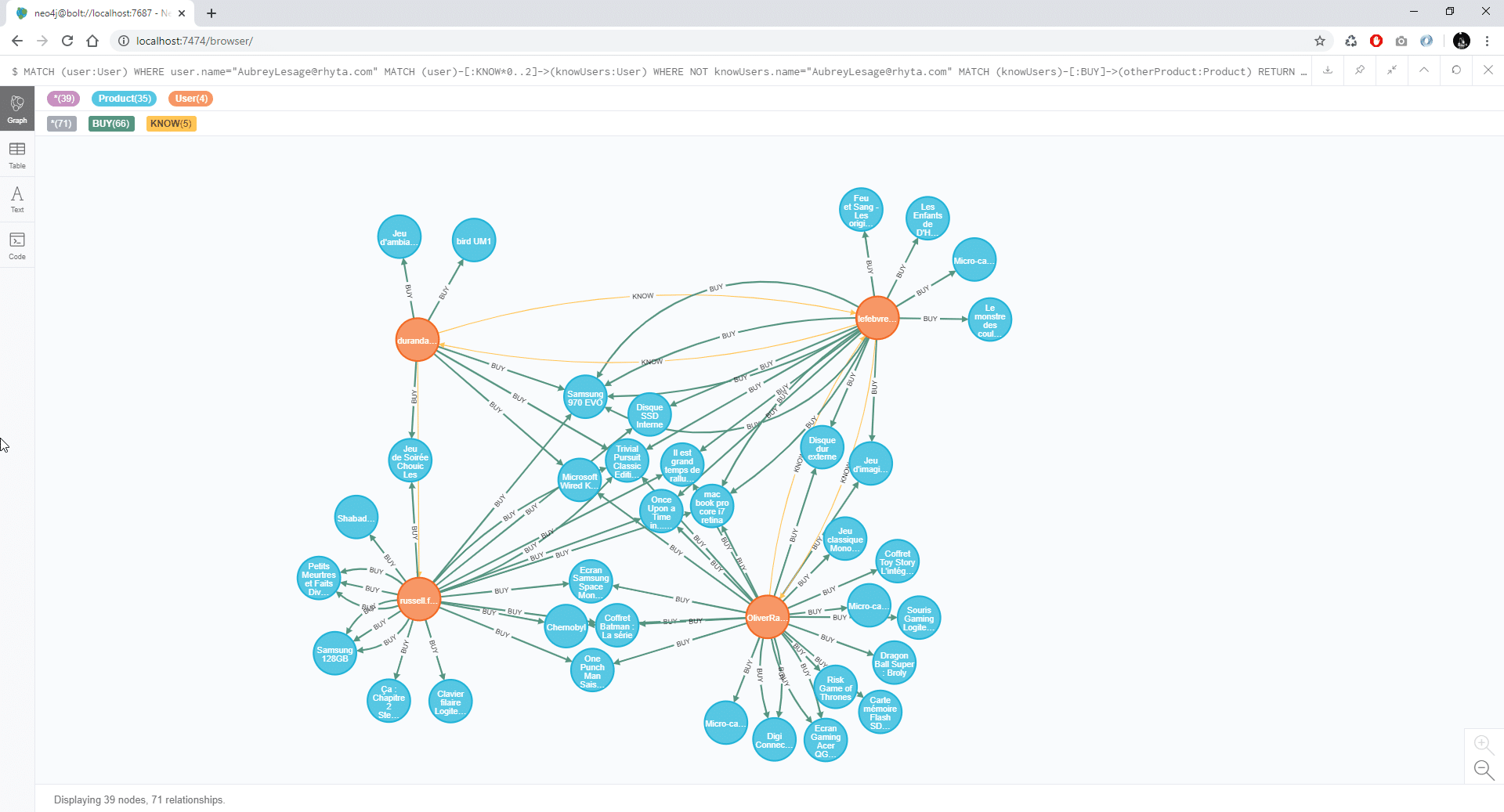
Les bases de données orientées graphe peuvent gérer des cas beaucoup plus complexe de relations. Dans l’exemple ci-dessus on cherche à obtenir la liste des produits achetés par les connaissances d’une certaine personne. Ce cas est plutôt courant dans l’usage des bases de données orientées graphe et donne beaucoup de difficulté aux bases de données relationnelle.
La requête en Cypher est relativement simple :
- on commence par sélectionner la personne concernée par la recherche
- on obtient les personnes de son entourage sur deux niveaux de profondeur. Les personnes qu’elle connaît peuvent avoir la personne principale de notre recherche peut faire partie des connaissances de ses connaissances. On l’exclus donc de cette sélection
- on sélectionne les produits qu’ils ont achetés
- et il ne reste plus qu’à retourner la liste des produits et les personnes qui les ont achetés
On ne souhaite pas forcément renvoyer l’intégralité des propriétés présents sur les nœuds. Dans ce cas il est possible de spécifier dans le RETURN les propriétés que l’on souhaite. Lors de l’exécution de la requête sur l’interface d’administration de Neo4J on aura un tableau au lieu du graphe de données.
[pastacode lang=”sql” manual=”MATCH%20(user%3AUser)%20WHERE%20user.name%3D%22AubreyLesage%40rhyta.com%22%0AMATCH%20(user)-%5B%3AKNOW*0..2%5D-%3E(knowUsers%3AUser)%20WHERE%20NOT%20knowUsers.name%3D%22AubreyLesage%40rhyta.com%22%0AMATCH%20(knowUsers)-%5B%3ABUY%5D-%3E(otherProduct%3AProduct)%0ARETURN%20collect(distinct%20knowUsers.name)%20%20%20%20%20%20%20as%20customers%2C%0A%09id(otherProduct)%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20as%20id%2C%0A%20%20%20%20%20%20%20otherProduct.name%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20as%20name%2C%0A%20%20%20%20%20%20%20otherProduct.price%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20as%20price%0AORDER%20by%20otherProduct.price%20DESC” message=”” highlight=”” provider=”manual”/]
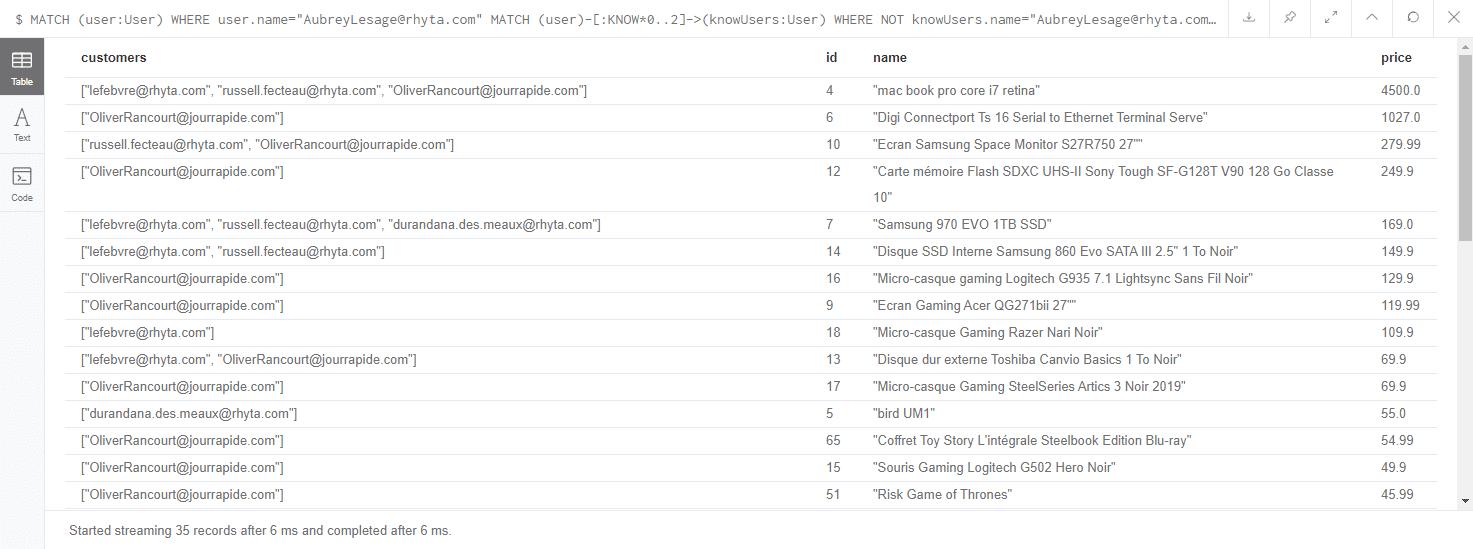
Le langage Cypher contient un ensemble de fonctions permettant de retravailler les données. On retrouve ce type d’usage dans l’exemple ci-dessus avec l’utilisation de la fonction collect qui va aggréger des propriétés. On retrouve énormément de fonctions, que ce soit pour des calculs mathématique, filtrage de données, calcul temporel, et bien d’autres. Ces fonctions sont également extensibles via des plugins. Les deux principaux plugins de Neo4J sont :
- APOC : qui est une collection d’utilitaires et fonctions pour Cypher (https://neo4j.com/developer/neo4j-apoc/)
- Graph-Algorithms : qui contient des algorithmes spécifiques pour détecter des similarités entres nœuds, chemin le plus court entre différentes relations et bien d’autres (https://neo4j.com/developer/graph-algorithms/)
Ecrire des informations
Le langage Cypher permet de lire, mais il permet également de créer, modifier et supprimer des données.
[pastacode lang=”sql” manual=”CREATE%20(car%3ACar%20%7B%20name%3A%20’Renault’%2C%20color%3A%20’Gray’%20%7D)%0ARETURN%20car” message=”” highlight=”” provider=”manual”/]
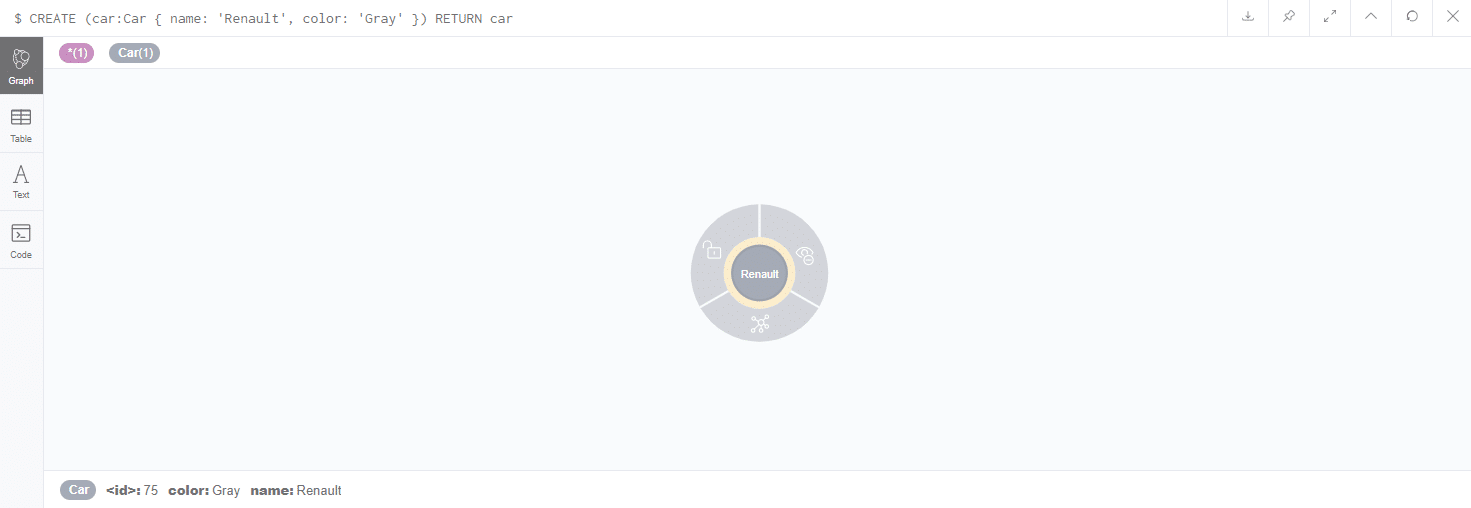
Les types de nœuds, relations et propriétés ne sont pas normalisés dans Neo4J. Il n’est donc pas nécessaire de définir un schéma par rapport à la structure de la données. Il est cependant possible de prédéfinir des types d’objets lors qu’on configure des contraintes (d’unicité par exemple) ou des indexes pour optimiser les accès à la base de données.
L’instruction CREATE va créer un nœud mais ne vérifie pas son existence au préalable. On pourra donc se retrouver avec des nœuds en doublons. Si on ne souhaite pas avoir de doublon on peut utiliser l’instruction MERGE. Dans ce cas si un nœud est déjà présent il sera modifié. La comparaison d’égalité est réalisée sur la propriété name. C’est elle qui est également affichée dans l’interface de gestion de Neo4J.
[pastacode lang=”sql” manual=”MERGE%20(car%3ACar%20%7B%20name%3A%20’Renault’%2C%20color%3A%20’Gray’%20%7D)%0ARETURN%20car” message=”” highlight=”” provider=”manual”/]
La suppression va nécessiter d’effectuer une recherche en amont pour sélectionner les nœuds à supprimer. La petite subtilité est que dans le monde des graphes, nos données peuvent être interconnectées. Il est donc important de détacher nos nœuds avant de les supprimer.
[pastacode lang=”sql” manual=”MATCH%20(car%3ACar)%20WHERE%20car.name%3D%22Renault%22%0ADETACH%20DELETE%20car” message=”” highlight=”” provider=”manual”/]

La mise en relation est très proche de la création de nœud. Il est nécessaire pour cela d’avoir deux nœuds (soit à la suite d’une création, ou d’un recherche) et de décrire la relation entre eux. On peut utiliser aussi bien l’instruction CREATE ou MERGE en fonction que l’on souhaite créer ou modifier des données.
[pastacode lang=”sql” manual=”%2F%2F%20create%20nodes%0ACREATE%20(car%3ACar%20%7B%20name%3A%20’Renault’%2C%20color%3A%20’Gray’%20%7D)%0ACREATE%20(parking%3AParking%20%7B%20name%3A%20’Parking%20du%20Mont-Blanc’%7D)%0A%0A%2F%2F%20create%20relationship%0ACREATE%20(car)-%5Br%3AHAS_SUBSCRIPTION%20%7B%20from%3A1577836800000%2C%20to%3A1585699200000%20%7D%5D-%3E(parking)%0A%0ARETURN%20car%2Cparking” message=”” highlight=”” provider=”manual”/]
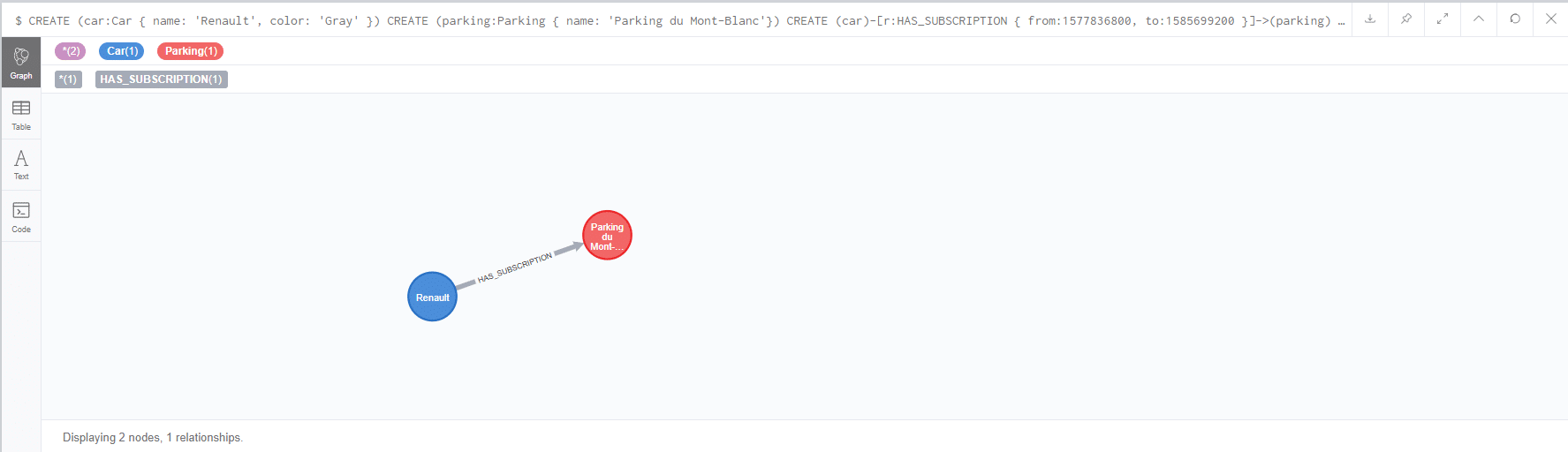
Comme pour la création des nœuds, il est possible d’ajouter des propriétés sur la relation soit dans le but d’ajouter de l’information sur cette relation soit pour de futures recherches. Dans l’exemple, nous précisons la date de début et de fin d’abonnement afin de pouvoir rechercher nos données par rapport à ces axes temporels.
[pastacode lang=”sql” manual=”MATCH%20(car%3ACar)-%5Br%3AHAS_SUBSCRIPTION%5D-%3E(parking%3AParking)%0A%20%20%20%20%20%20%20WHERE%20r.from%20%3E%3D%20datetime(‘2020-01-01T00%3A00%3A00.000%2B0100’).epochMillis%0A%0ARETURN%20car%2C%20parking” message=”” highlight=”” provider=”manual”/]
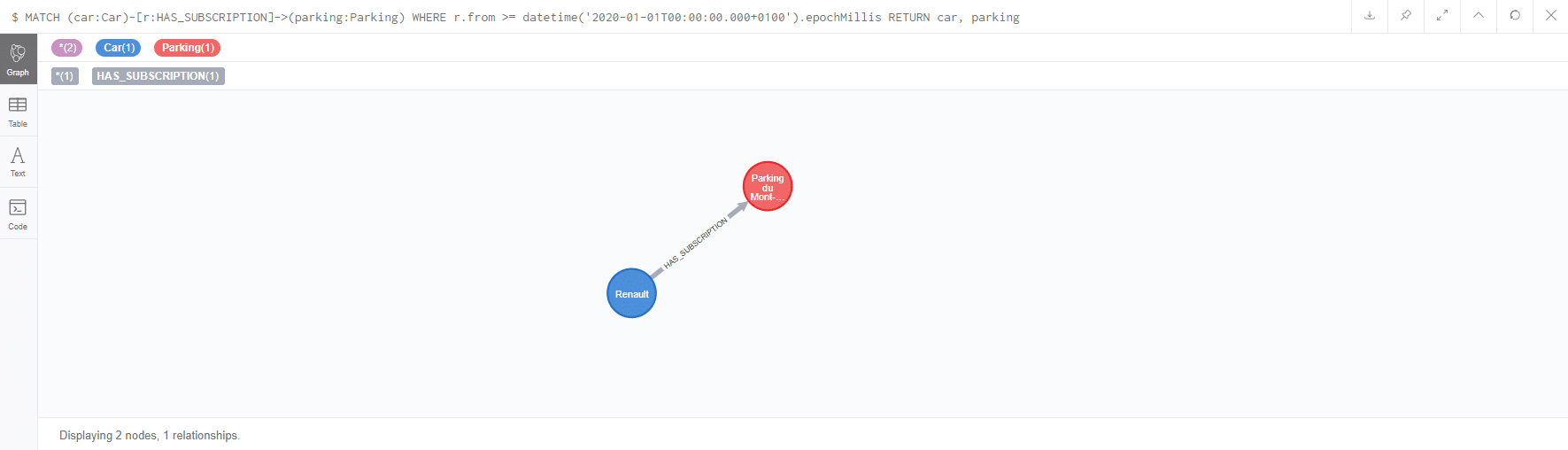
Afin d’effectuer des recherches utilisant les propriétés des relations, on effectue une requête très similaire à celle utilisée dans le cadre d’une recherche sur les propriétés des nœuds. Il est juste nécessaire d’affecter la relation sur une variable (dans l’exemple la variable r). Une fois cette variable affectée, il est possible d’avoir accès à ses différentes propriétés. On utilise la fonction datetime pour générer une date et ainsi la comparer cette date avec la date de début d’abonnement.
Conclusion
Comme nous avons pu le voir l’utilisation de Neo4J est très accessible. Des outils comme docker nous permettent de rapidement installer et commencer nos premiers essais sur cette technologie.
Le langage Cypher permet un apprentissage progressif. Les premières requêtes pour des cas simple ne sont pas trop éloignées des conceptes du langage SQL. La maîtrise de requêtes complexes se fait au fur et à mesure. La documentation présente sur le site de Neo technologie contribuent énormément à cet apprentissage.
L’interface de gestion de Neo4J nous permet d’expérimenter nos requêtes et de visualiser nos données. C’est un outil précieux pour l’apprentissage de Neo4J et son exploitation.
Une fois notre base de données initialisée, il sera possible de l’exploiter via une application. C’est ce que l’on découvrira dans le prochain article axé sur l’intégration de Neo4j avec Spring data.